英伟达算力垄断面临挑战,全球巨头竞逐自研AI芯片新赛道
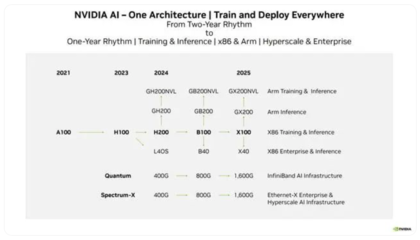
在人工智能浪潮席卷全球的当下,算力已成为驱动技术进化的核心引擎。长期以来,英伟达凭借其强大的GPU(图形处理器)产品线,特别是为AI和高性能计算优化的架构,在AI训练和推理市场建立了近乎垄断的地位。其CUDA软件生态构筑了深厚的护城河,使得众多开发者与企业形成了路径依赖。随着AI模型规模的指数级增长与应用场景的不断拓宽,单一的算力供应格局正面临前所未有的挑战。
打破垄断的驱动力首先源于巨大的市场需求与成本考量。英伟达高端芯片的供需失衡与高昂价格,迫使全球各大科技巨头重新审视供应链安全与自主可控的重要性。从云计算厂商、互联网巨头到汽车制造商,一场声势浩大的自研AI芯片竞赛已然拉开帷幕。
头部云厂商率先破局:
亚马逊AWS早已推出自研的Inferentia和Trainium芯片,专门用于AI推理和训练,旨在降低其云服务客户的成本。谷歌的TPU(张量处理单元)发展至今已历多代,在其搜索、翻译及AI服务中扮演关键角色,并已通过云平台对外提供服务。微软也携手合作伙伴,为Azure云平台定制AI芯片,以减少对英伟达的依赖。这些云服务巨头的共同策略是,通过自研专用芯片优化自身核心业务的效率,同时将算力作为一种更具性价比的服务输出,从而在底层基础设施层面构建差异化优势。
互联网与科技公司深入核心:
Meta(Facebook)、特斯拉等公司基于自身庞大的特定应用场景(如内容推荐、自动驾驶),也投身自研芯片行列。特斯拉的FSD(全自动驾驶)芯片便是典型代表,专为自动驾驶视觉数据处理和决策设计,实现了软硬件的深度垂直整合。这种针对特定算法和任务进行优化的专用集成电路(ASIC),往往能在能效比和性能上超越通用GPU,满足其产品迭代的独特需求。
传统芯片巨头与初创企业群雄并起:
AMD通过升级的MI300系列等产品线,正积极抢夺数据中心AI加速器市场。英特尔则凭借Gaudi系列等,持续发力AI训练与推理领域。与此全球范围内涌现出众多AI芯片初创公司,如中国的寒武纪、壁仞科技等,它们从不同的架构创新(如存算一体、新型互联技术)入手,试图在细分市场找到突破口。
数据处理范式的演变构成深层变量:
AI的演进不仅要求芯片算力的提升,更对数据处理的方式提出了新要求。大模型训练涉及海量非结构化数据(文本、图像、视频)的并行处理、高效存储与快速吞吐。未来的AI芯片竞赛,不仅仅是峰值算力的比拼,更是内存带宽、互联技术、能耗效率以及编译器、软件栈等全栈能力的综合较量。能够更高效处理特定数据流、与算法框架深度耦合的架构,将更有可能脱颖而出。
挑战英伟达的霸主地位绝非易事。其数十年来构建的CUDA生态系统,包含了庞大的开发者社区、成熟的工具链和丰富的优化库,形成了强大的网络效应和用户黏性。新兴芯片厂商不仅要提供有竞争力的硬件,更需要在软件生态上投入巨大资源,以降低开发者的迁移门槛。
英伟达的算力垄断正从多个维度受到冲击。市场对多元化、专业化、低成本算力的迫切需求,是这场竞赛的根本动力。短期内,英伟达凭借其生态优势仍将保持领先,但市场格局正从“一家独大”向“一超多强”乃至多元化供应链演进。最终的赢家,很可能不是单一产品的胜利,而是不同架构在特定场景和应用中找到了最优解。这场围绕AI芯片与数据处理能力的全球竞赛,必将加速人工智能技术的普惠与深化,最终推动整个产业进入一个更加繁荣与健康的竞争新阶段。
如若转载,请注明出处:http://www.quboluo.com/product/34.html
更新时间:2026-06-18 05:49:21